ImageBind АI alat otvorenog koda je prvi model vјeštačke inteligencije koji može da poveže informacije iz šest modaliteta
Meta je razvila AI alat otvorenog koda pod nazivom “ImageBind” koji predviđa veze između podataka slične načinu na koji ljudi percipiraju ili zamišljaju okruženje.
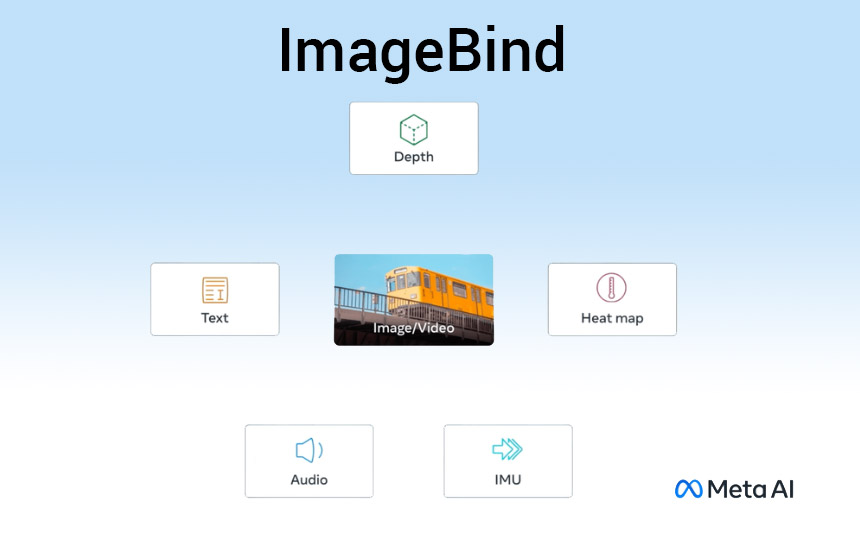
Dok generatori slika kao što su Midjourney, Stable Diffusion i DALL-E 2 uparuju reči sa slikama, omogućavajući vam da generišete vizuelne scene samo na osnovu tekstualnog opisa, ImageBind stvara širu mrežu. Može da poveže tekst, slike/video zapise, audio, 3D mjerenja (dubina), podatke o temperaturi (termičke) i podatke o kretanju (iz inercijalnih mernih jedinica) — i to radi bez potrebe da se prvo obučava za svaku mogućnost. To je rana faza okvira koji bi na kraju mogao da generiše složena okruženja od unosa jednostavnog kao što je tekstualni upit, slika ili audio snimak (ili neka kombinacija od tri)..
ImageBind možete gledati kao približavanje mašinskog učenja ljudskom učenju. Na primjer, ako stojite u stimulativnom okruženju kao što je prometna gradska ulica, vaš mozak (uglavnom nesvjesno) apsorbuje prizore, zvukove i druga senzorna iskustva kako bi zaključio informacije o automobilima i pješacima u prolazu, visokim zgradama, vremenu i još mnogo toga.
Ljudi i druge životinje su evoluirali da obrađuju ove podatke za našu genetsku prednost: preživljavanje i prenošenje naše DNK. (Što ste svjesniji svog okruženja, to više možete da izbjegnete opasnost i da se prilagodite svom okruženju radi boljeg preživljavanja i prosperiteta.)
Kako se računari približavaju oponašanju multisenzornih veza životinja, oni mogu da koriste te veze da generišu potpuno ostvarene scene zasnovane samo na ograničenim dijelovima podataka.
Meta AI u svojem blogu piše: “Danas predstavljamo pristup koji približava mašine za korak bliže ljudskoj sposobnosti da uči istovremeno, holistički, i direktno iz mnogih različitih oblika informacija, bez potrebe za eksplicitnim nadzorom. Izgradili smo i koristili ImageBind otvorenog koda, prvi model vјeštačke inteligencije koji može da poveže informacije iz šest modaliteta. Model uči jedinstveni prostor za ugradnju ili zajednički prostor za prikaz, ne samo za tekst, slike/video i audio, već i za senzore koji hvataju dubinu (3D), toplotu (infracrvene) i inercijalne merne jedinice (IMU), koje izračunavaju kretanje i položaj. ImageBind oprema mašine holističkim razumijevanjem koje povezuje objekte na fotografiji kako će zvučati, njihov 3D oblik, koliko toplo ili hladno i kako se kreću.”
ImageBind može da nadmaši prethodne specijalizovane modele obučene pojedinačno za jedan određeni modalitet, ali što je najvažnije, pomaže u unapređenju vještačke inteligencije omogućavajući mašinama da bolje analiziraju mnogo različitih oblika informacija zajedno.
Upotreba ImageBind AI alata
Što se tiče toga šta bi još moglo da se uradi sa ovom novom igračkom, to jasno ukazuje na jednu od ključnih ambicija Mete: VR, miješana stvarnost i metaverzum. Na primjer, zamislite buduće slušalice koje mogu da konstruišu potpuno realizovane 3D scene (sa zvukom, pokretom itd.) u pokretu. Ili, programeri virtuelnih igara bi možda mogli da je iskoriste da uklone veći dio posla iz svog procesa dizajna. Slično tome, kreatori sadržaja mogli bi da naprave impresivne video zapise sa realističnim zvučnim pejzažima i pokretima na osnovu samo teksta, slike ili audio unosa.
Takođe je lako zamisliti alatku kao što je ImageBind koja otvara nova vrata u prostoru pristupačnosti, generišući multimedijalne opise u realnom vremenu kako bi pomogli osobama sa oštećenjem vida ili sluha da bolje sagledaju svoje neposredno okruženje.
ImageBind je dio Meta-inih napora da stvori multimodalne AI sisteme koji uče iz svih mogućih tipova podataka oko sebe. Kako se broj modaliteta povećava, ImageBind otvara vrata istraživačima da pokušaju da razviju nove, holističke sisteme, kao što je kombinovanje 3D i IMU senzora za dizajniranje ili iskustvo impresivnih virtuelnih svjetova. ImageBind takođe može da pruži bogat način za istraživanje uspomena – traženje slika, video zapisa, audio datoteka ili tekstualnih poruka koristeći kombinaciju teksta, zvuka i slika.
Među primjerima koje Meta ističe je generisanje zvuka sa fotografija i video zapisa, što znači da ImageBind može da generiše zvukove koji odgovaraju onome što se nalazi na slikama ili video snimku, pa će na primjer dodijeliti fotografiju psa koji laje, režanje tigra, voz uz zvuke pokretnih šina i sirena, dok će fotografiji savijanja grana u šumi dodati zvižduk vetra.
Meta smatra da se tehnologija širi izvan svojih trenutnih šest „čula“.
„Iako smo istražili šest modaliteta u našem trenutnom istraživanju, vjerujemo da će uvođenje novih modaliteta koji povezuju što više čula – poput dodira, govora, mirisa i signala fMRI mozga – omogućiti bogatije modele veštačke inteligencije usmerene na čovjeka”, ističu iz Mete.
Programeri zainteresovani za istraživanje ovog novog sandbox-a mogu početi tako što će da zarone u Meta-in open-source kod.
(Meta)


